Couprie, Pierre. "Analytical Approaches to Electroacoustic Music Improvisation." Organised Sound 27, no. 2 (2022): 117-130. doi:10.1017/S1355771821000571.
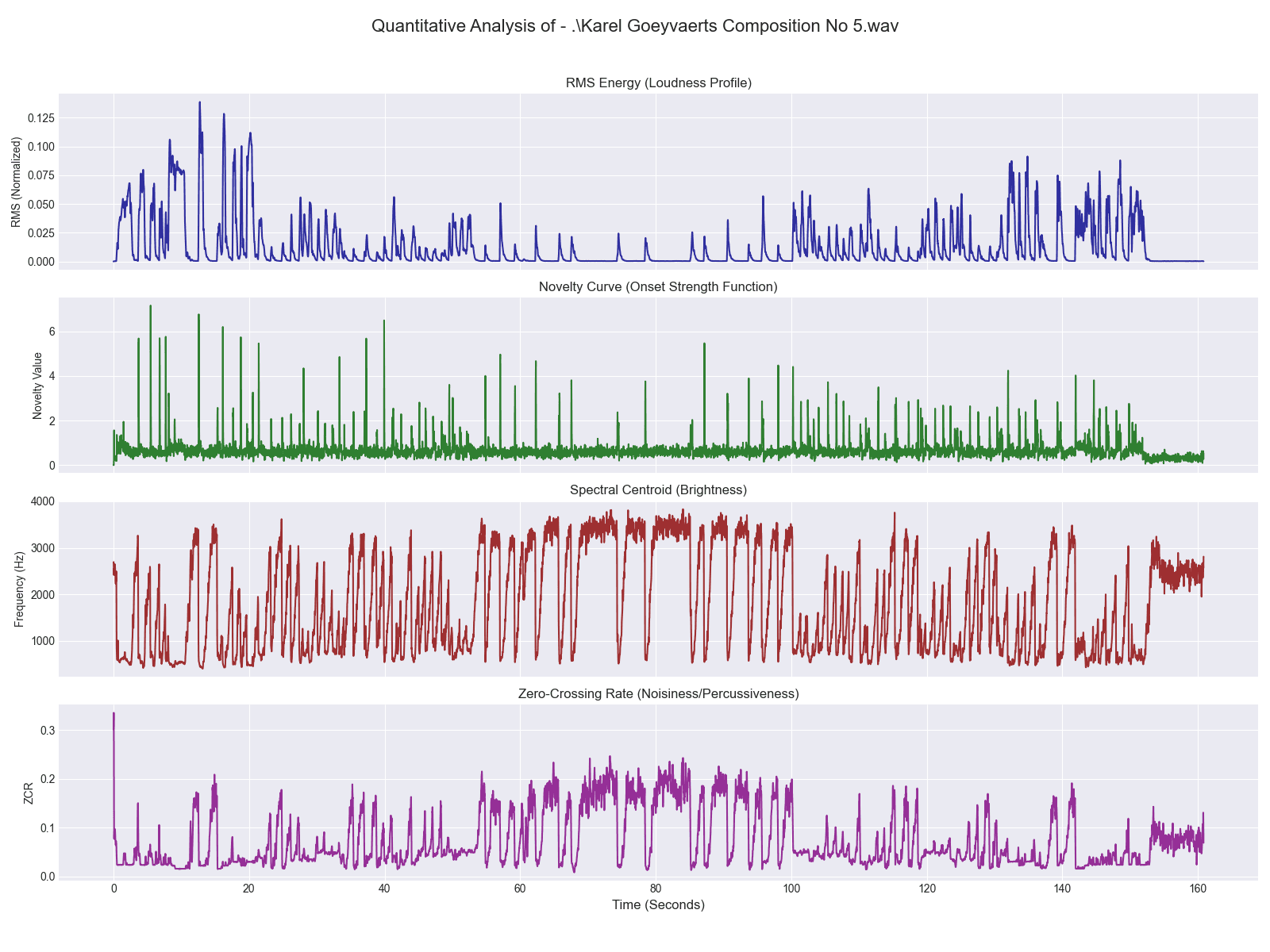
Dean, Roger T. "Modelling Perception of Structure and Affect in Music: Spectral Centroid and Wishart’s Red Bird." Empirical Musicological Review Vol. 6, no. 2, 2011 [https://pdfs.semanticscholar.org/071d/02885984e94e047f07e29a5fd4ce73ade799.pdf].
Jensenius, Alexander Refsum, ed. Sonic Design - Explorations Between Art and Science. Springer, 2024. [https://link.springer.com/content/pdf/10.1007/978-3-031-57892-2.pdf].
Laske, Otto. "Toward a Definition of Computer Music." Paper presented at the International Computer Music Conference, Denton, TX, 1981. [http://hdl.handle.net/2027/spo.bbp2372.1981.005].
Laske, Otto. "Understanding Music with AI." Paper presented at the International Computer Music Conference, Montreal, QC, 1991. [http://hdl.handle.net/2027/spo.bbp2372.1991.045].
Martins, Fellipe Miranda. "Analysis informed by audio features associated with statistical methods: a case study of Imago (2002) by Trevor Wishart." Paper presented at the 5th International Meeting of Music Theory and Analysis, 2019. [https://repositorio.ufmg.br/bitstream/1843/51299/2/Analysis%20informed%20by%20audio%20features%20associated%20with%20statistical%20methods%20a%20case%20study%20on%20%E2%80%98Imago%E2%80%99%20%282002%29%20by%20Trevor%20Wishart.pdf].