 Verena Szojak, Verena Praher
Verena Szojak, Verena Praher  Verena Praher
Verena Praher 
17 Minuten
A glimpse into explainable AI
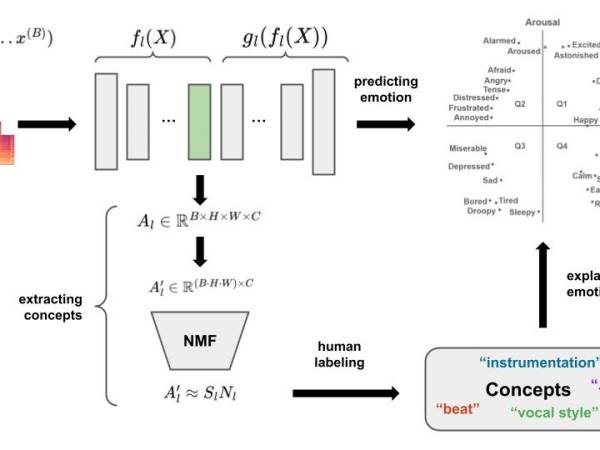
Figure 1: The upper part schematically shows the architecture for predicting emotion. The upper right part shows emotion quadrants in valence-arousal space, with indicative positioning of various emotion words. The lower part shows how concepts of an arbitrary layer l are extracted and labeled by humans to later explain the emotion predictions.
Deep AI model architectures have drastically increased model performance1. However, with the increased model complexity, how an output is obtained is not understood2, therefore these models are often called “black boxes”. Shedding light into these black boxes is important for model users and developers: Users need to be able to trust model decisions3. A model learned with a large amount of data that might contain human bias or spurious correlations, which is then reflected in decisions4. Developers need a deep understanding to improve models5.
To make models more interpretable, several explainable AI (XAI) methods have been introduced. One distinguishes between ante-hoc (training an explainable model) and post-hoc (making a pretrained model explainable), model-specific (XAI method works for one model class, e.g. CNNs) and model-agnostic (XAI method works for all kinds of models), local explanations (explaining one sample), and global explanations (explaining a model, class or subset of samples)6. For a deep dive into these different methods, we recommend looking into Interpretable Machine Learning: A Guide for Making Black Box Models Explainable.
Concept-based explanations have emerged as one approach, offering high-level human-friendly explanations in the form of concepts. “A concept can be any abstraction, such as a color, an object, or even an idea”7 and “is generalized from particular instances”8. For our MER model such higher-level generalizations could relate to musical features, e.g. “instrumentation”, “beat”, “vocal style”, etc.
The goal of this article is to address drawbacks of one method that extracts concepts without prior knowledge about what a concept could be and to gain more insights into learned concepts. This will get us closer to providing users with high-level, human-understandable explanations. We will study this in the context of a specific Music Information Retrieval (MIR) task – music emotion recognition (MER) from audio.
Explaining a model using concepts
We first need to extract concepts from our model. Concept Activation Vectors (CAVs) represent these “concepts” in the space of a model layer’s activation map9. Then, we can use these concepts to get a deeper understanding of what our model has learned to classify the different music emotions.
Obtaining Concepts from a Model
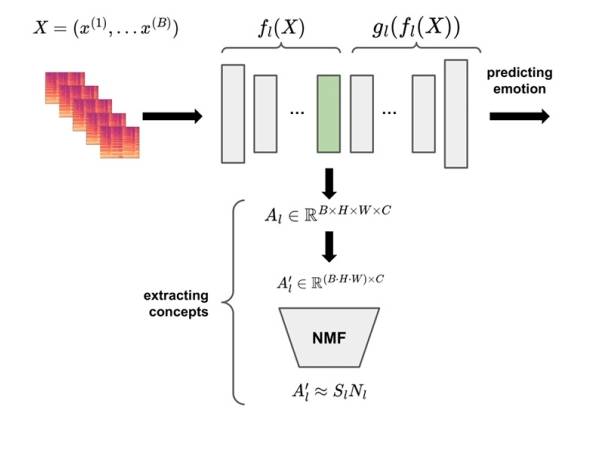
Figure 2: Extracting concepts of an arbitrary layer l.
We base our explainer on work by Zhang et al 10 and Kim et al 11. The prediction Y = m(X) for a trained convolutional model m and input audios X can be split into two parts at any layer l: Y = m(X) = gl(fl(X)). fl(X) computes activations Al ∈ RB×H×W×C, where B is the number of samples in the batch, H and W are the height and width of the activation map, and C is the number of channels. gl(Al) then computes Y (i.e., gl represents the part of the network ‘above’ layer l and continues the forward pass). To obtain Concept Activation Vectors (CAVs) for a layer l of interest, we use Non-negative Matrix Factorization (NMF)12. This algorithm learns to represent a non-negative matrix by two smaller non-negative matrices. One of the smaller matrices holds the concepts and the other one is the encoding which includes the information on how the concepts should be combined. Consequently, NMF can be considered as learning a concept dictionary. An intuitive visualization is provided here.
We use NMF to obtain non-negative CAVs (NCAVs) for a specific model layer l by following these steps:

Figure 3
Desired Concept Properties
In recent years, the evaluation of XAI methods with respect to desired properties of concepts has become more important. The literature mentions properties such as coherence, meaningfulness, and importance13, interpretability and fidelity14,15. For this work we will focus on coherence and, meaningfulness. Concept-based explanations are more interpretable than other types of explanations by design16.
We stipulate that concepts used for explaining models in MIR should be:
- coherent: examples of a concept are expected to be perceptually similar to each other, and different from other examples17;
- meaningful: different humans should assign similar meanings to examples of the same concept18;
Evaluation Metrics for Concepts
With the resulting three matrices, Sl, Nl, A′l, we can compute several properties. For more detailed information, we refer to our paper.
Average Concept Presence: This metric calculates a score that relates to the strength of a concept in a sample19,20. We will use this score to rank examples for each concept.
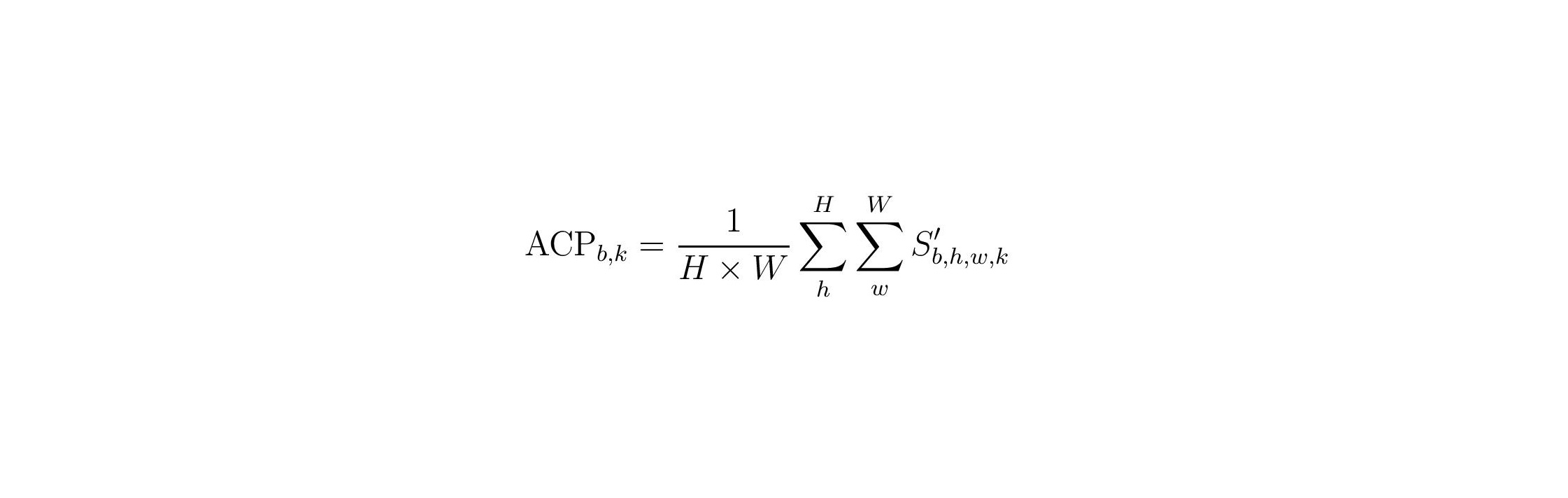
Figure 4
Local and Global Explanations: To measure how relevant a concept k in layer l (nlk denotes the corresponding CAV) is for predicting a certain class q for a single input example (local explanation), we can use the conceptual sensitivity SENSk,l,q 21.
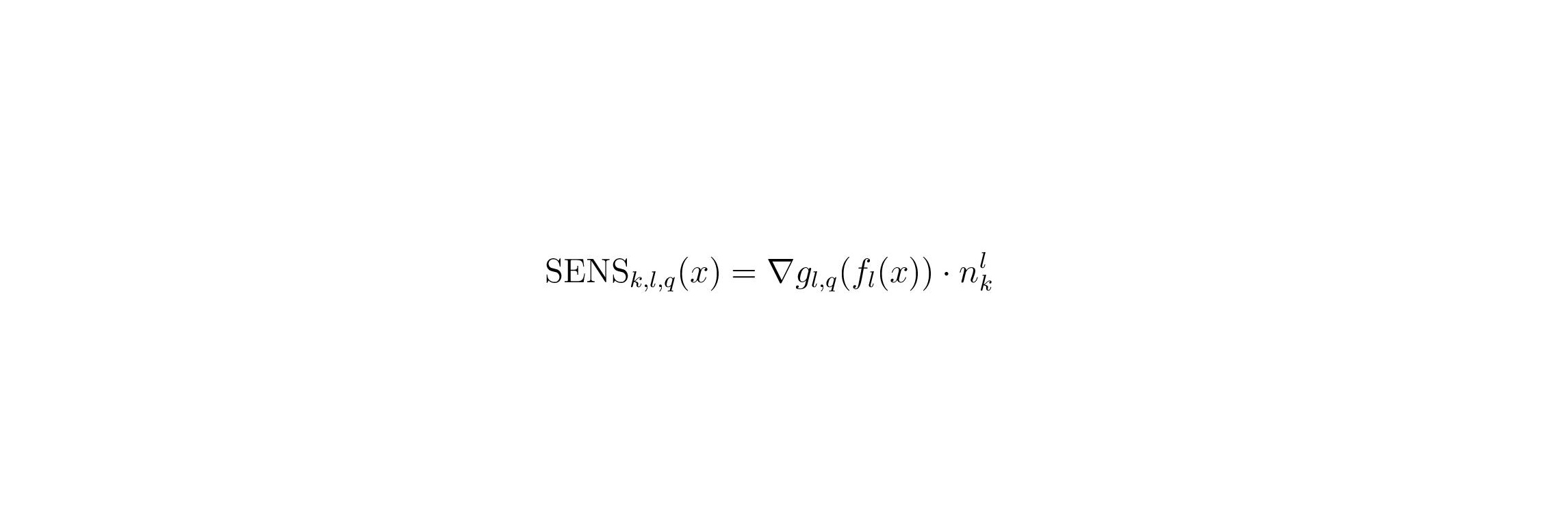
Figure 5
To obtain a global explanation, i.e., to answer the question which concept is relevant for predicting a certain class in general, we can compute CAV scores: we take a set of examples belonging to the class of interest and compute the ratio of examples with positive conceptual sensitivity22.
Predicting Music Emotions
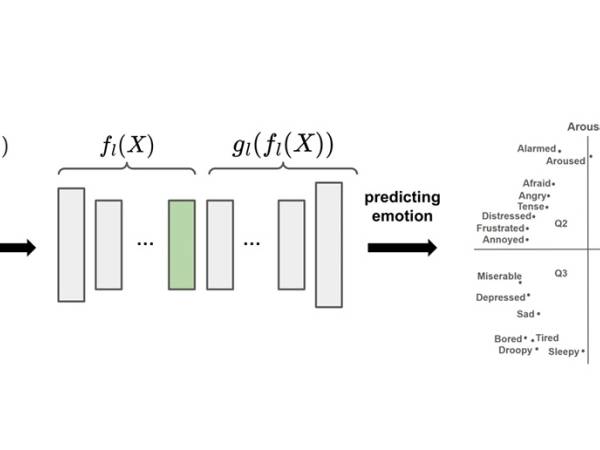
Figure 6: Architecture for predicting emotion from given spectrograms.
We have all prerequisites to obtain explanations from a model. Now, we need a model that we can analyse. In this section, we describe dataset, model architecture and training setup for our model that classifies input audios into a set of discrete emotion classes.
4Q Audio Emotion Dataset
Panda et al.23, 24 published the “4Q Audio Emotion Dataset” with a wide variety of standard and novel audio features for MER. It contains audio snippets and 1714 audio features for 900 music pieces covering a broad set of musical styles. Each piece is annotated into one of the four quadrants of Russell’s25 valence-arousal space (225 audio samples per quadrant). These quadrants (see the upper right part of Figure 6) are generally equated with four basic emotions; happiness/exuberance (Q1); anxiety (Q2); depression (Q3); and contentment (Q4). The four quadrant labels serve as discrete target classes for our emotion recognition model.
The 1714 features consist of 898 ‘standard‘ descriptors (e.g., zero crossing rate, low energy rate, etc.) computed using different toolboxes and 816 ‘novel’ features (including but not limited to melodic, rhythmic, musical texture and expressivity features). More details can be found in the papers introducing this dataset: Musical Texture and Expressivity Features for Music Emotion Recognition, Novel Audio Features for Music Emotion Recognition.
This dataset serves two purposes: (1) the audio is used to train our fully convolutional MER model and (2) the set of provided audio features will be used to label our extracted concepts.
Music Emotion Recognition Model
For training an end-to-end MER model, we base our implementation on a fully convolutional NN (FCN)26, 27. Our model consists of 5 convolutional layers (with 32, 64, 64, 64 and 32 channels), each followed by BatchNorm28, a ReLU 29 to ensure nonnegativity of activations and max pooling. The convolutional layers are followed by a linear layer, Dropout (p=0.5) and a Softmax layer. This architecture can take full-length audio input (30 seconds in our experiments) which is useful since the audio features we are comparing to are computed on the full audio spectrograms.
We performed grid search to determine the optimal hyperparameters. The highest validation accuracy was achieved on a model trained for 100 epochs using Adam30 with a learning rate of 5 ∗ 10−4 and a batch size of 8. We retrained the best model 10 times and report the performance on the test set in terms of accuracy: 0.734 ± 0.014.
Explaining Music Emotion
With the trained music emotion recognition model and the outlined explainability approach, we compute CAVs using training data for each of the 5 convolutional layers from our model and analyse them with respect to the desired properties: coherency and meaningfulness.
Listening Experiment
We designed a listening experiment to investigate whether the extracted concepts are coherent (examples of a concept are expected to be perceptually similar to each other, and different from other examples31) and meaningful (different humans should assign similar meanings to examples of the same concept 32). Regarding coherence, we draw inspiration from recent work who have conducted intruder detection experiments33, 34, inspired by 35. Participants are presented with a set of examples, where all except one belong to the same concept. They are asked to identify the one that does not (termed intruder). To test meaningfulness, we ask the participants about the similarities among the non-intruders. We used the tool SosciSurvey36 to create the online questionnaire.
Participants are presented with 10 sets (2 per model layer) of 4 audio examples each. Each set consists of the 3 audio examples with the highest ACP for a concept of interest, and one intruder (which has the lowest ACP for the selected concept).
We take a 10 second snippet (which has the highest/lowest ACP for this piece) for each audio example. For each set we ask the following three questions:
- Which of the following pieces of music is different from the other three pieces?
- How confident are you that the piece you selected is different from the others? [Four checkboxes ranging from “I am very confident” to “I had to guess”.]
- Please describe the common characteristics shared by the three similar pieces. What makes these three pieces similar to each other?
For the 4 CAVs of the first model layer, we provide the audio samples. These are provided by Panda et al. (2018) 37 and can be found here. Can you detect the intruder?
| Concept 1 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Concept 2 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Concept 3 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Concept 4 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
Answers: Ex3; Ex2; Ex3; Ex1
In the following, “item” refers to a set consisting of 4 audios (in total 40 seconds of audio) and the corresponding 3 questions.
Overall Statistics
To reduce the variability among the participants, we asked people between 25 and 35 years who have learned to play at least one instrument to participate. To not bias the participants’ answers they were not aware that the prediction task was music emotion. We recruited 13 participants. While we have to be careful with drawing conclusions from this small number, it allows us to do a qualitative analysis by asking and analysing free text questions. The median time spent by a participant for evaluating all 10 items (10 × 4 × 10 seconds = 6.67 minutes of audio) was 22.15 minutes (IQR = 14.85, 27.5).
Extracted Concepts are Coherent
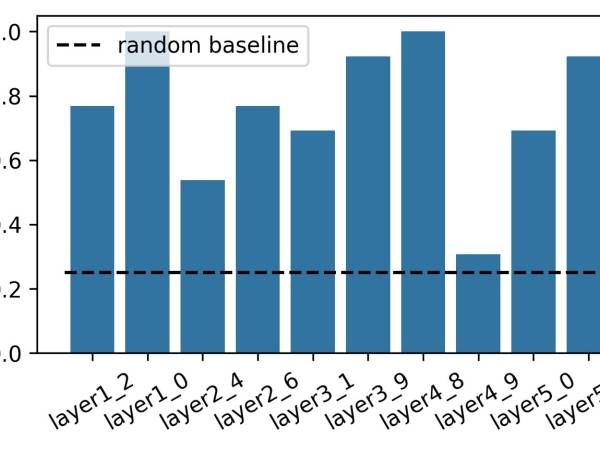
Figure 7: This figure shows the intruder detection rate for each of the 10 items in the questionnaire labeled by the corresponding layer and CAV.
Participants correctly identified 76.15% (±21.89) of the intruders (ranging from 30.77% to 100% per set). The intruder detection rate per concept is visualized in Figure 7.
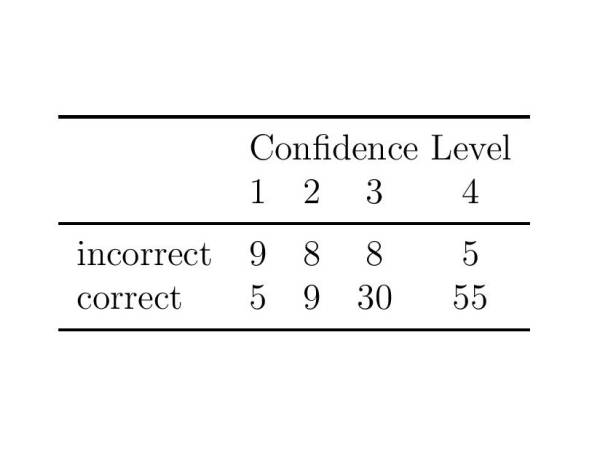
Figure 8: Reported confidence scores for correctly and in correctly detected intruders. The confidence scores range from 1 (“I had to guess”) to 4 (“I am very confident.”).
The participants were also asked to state their confidence level, the results are summarized in Figure 8. The listeners were very confident about their correct choices, and selected “I had to guess.” more often when they selected a wrong sample as the intruder.
These results let us conclude that most of the concepts that we presented to our participants are coherent, meaning that examples belonging to the concept are perceptually similar to each other while they are different from other examples38.
Extracted Concepts are Meaningful
To evaluate whether the extracted concepts are meaningful we look into the participants answers to Question 3 (Please describe the common characteristics shared by the three similar pieces. What makes these three pieces similar to each other?).
We take a closer look at all answers given for two of the items, one for which all participants detected the correct intruder (layer4_8), and the most difficult one - with only 30.77% correct answers (layer4_9).
| layer 4, concept 8 | ||
Audio file
©
| Audio file
©
| Audio file
©
|
| layer 4, concept 9 | ||
Audio file
©
| Audio file
©
| Audio file
©
|
For both items we (manually) extracted terms that were used to describe what the participant thought were the three similar audio snippets. The extracted terms for both items are visualized:

Figure 9: Word clouds summarising the descriptions that participants gave for Layer 4 CAV8: all terms center around the notion of ‘genre’.

Figure 10: Word clouds summarising the descriptions that participants gave for Layer4 CAV9: no clear semantic focus can be identified.
The answers for the case where the concept was clearly grasped, with 100% agreement on the intruder, layer4_8, have a clear musical meaning, essentially centering around the notion of genre. This resonates with observations by Eerola39 on the importance of genre for emotion prediction and suggests that genre should generally be considered for naming concepts in this context. For the case where participants had difficulties detecting the intruder, layer4_9, no semantic focus is to be expected, as the intruder identification accuracy of the participants was barely above the baseline.
To further assess the meaningfulness of CAVs, we look into the aggregated CAV scores for layer1 (audios are provided above) to assess whether CAVs contribute positively to one of the 4 classes/emotion quadrants. Here, we make use of conceptual sensitivity SENSk,l,q(x) and show CAVs that contribute positively for at least half of the samples of a specific emotion quadrant.

Figure 11: Abstracted CAV Scores for layer1. Scores ≥ 0.5 appear as ‘+’, values < 0.5 as ‘o’.
Let us focus on the concepts that were part of the listening experiment (CAV0, CAV2), since we have human annotations for these.
- CAV0, which has high CAV scores for emotion classes Q1 (0.57) and particularly Q2 (0.70), is described as “energetic”, “fast-paced”, “loud”, and aspects like “aggressive vocals”, “vocal style”, “guitar with distortion”, and “drums” are highlighted.
- CAV2, which has a high score for Q1 (0.77), is described as “harmonic”, “melodic”, “romantic”, and participants mentioned aspects like “melodic singing” and “singing is clean and happy”.
These concept characterizations (indirectly obtained via our listening study) are intuitively compatible with the emotions that the respective emotion quadrants represent (Q1 is generally associated with ”happy” and ”excited”, Q2 with emotions such as ”tense”, ”angry”, ”distressed”).
Conclusion
In this article, we described one approach to extract concepts from a pretrained model and applied it to a deep music emotion recognition model to explore desired concept properties. We conducted a listening experiment that showed that the extracted concepts are coherent and meaningful.
There is still room for future work. Without human labeling, the extracted concepts do not have any meaning. Manually labeling them can become time-consuming when extracting several concepts for all layers. To test whether we can automatically label the extracted concepts that explain the high-level emotion predictions and get the most relevant naming, we propose in our paper an approach using the Spearman rank correlation40 and ACP for low- and mid-level descriptors. While we can automatically assign low- and mid-level meaning to the concepts, the listening experiment has shown that this is not what humans use to describe cohesive examples - concept-based explanations in MIR might require multiple levels of labels assigned to each concept; and we might have to incorporate automatic music tagging models41, 42 that can provide richer labels for giving meaning to the concepts.
V. Praher, V. Szojak und G. Widmer, “Concept-based Explanations for Music Emotion Recognition“, in Proceedings of the 22nd Sound and Music Computing Conference (SMC2025), Graz, July 2025, Graz, Austria, Juli 2025, S. 234–241. doi: 10.5281/zenodo.15837275.
- 1
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, pp. 436–44, 05 2015.
- 2
W. Samek and K.-R. Muller,¨ Towards Explainable Artificial Intelligence. Cham: Springer International Publishing, 2019, pp. 5–22. [Online]. Available: https://doi.org/10.1007/978-3-030-28954-6 1
- 3
R. Fong and A. Vedaldi, Explanations for Attributing Deep Neural Network Predictions. Cham: Springer International Publishing, 2019, pp. 149–167. [Online]. Available: https://doi.org/10.1007/978-3-030-28954-6 8
- 4
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, and D. Pedreschi, “A survey of methods for explaining black box models,” ACM Comput. Surv., vol. 51, no. 5, Aug. 2018. [Online]. Available: https://doi.org/10.1145/3236009
- 5
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in Computer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 818–833.
- 6
C. Molnar, Interpretable Machine Learning, 3rd ed., 2025. [Online]. Available: https://christophm.github.io/ interpretable-ml-book
- 7
C. Molnar, Interpretable Machine Learning, 3rd ed., 2025. [Online]. Available: https://christophm.github.io/ interpretable-ml-book
- 8
“concept,” https://www.merriam-webster.com/dictionary/concept, accessed: 2025-07-11
- 9
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 10
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 11
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 12
D. D. Lee and H. S. Seung, “Learning the Parts of Objects by Non-negative Matrix Factorization,” Nature, vol. 401, no. 6755, pp. 788–791, Oct 1999.
- 13
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 14
M. T. Ribeiro, S. Singh, and C. Guestrin, “”Why Should I Trust You?”: Explaining the Predictions of Any Classifier,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016. ACM, 2016, pp. 1135–1144.
- 15
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 16
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 17
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 18
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 19
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 20
F. Foscarin, K. Hoedt, V. Praher, A. Flexer, and G. Widmer, “Concept-Based Techniques for ”Musicologist-Friendly” Explanations in Deep Music Classifiers,” in Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022, Bengaluru, India, December 4-8, 2022, 2022, pp. 876–883.
- 21
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 22
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 23
R. Panda, R. Malheiro, and R. P. Paiva, “Musical Texture and Expressivity Features for Music Emotion Recognition,” in Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, September 23-27, 2018, 2018, pp. 383–391.
- 24
R. Panda, R. Malheiro, and R. P. Paiva, “Novel Audio Features for Music Emotion Recognition,” IEEE Trans. Affect. Comput., vol. 11, no. 4, pp. 614–626, 2020.
- 25
J. A. Russell, “A Circumplex Model of Affect,” Journal of personality and social psychology, vol. 39, no. 6, p. 1161, 1980.
- 26
K. Choi, G. Fazekas, and M. B. Sandler, “Automatic Tagging Using Deep Convolutional Neural Networks,” in Proceedings of the 17th International Society for Music Information Retrieval Conference, ISMIR 2016, New York City, United States, August 7-11, 2016, 2016, pp. 805–811.
- 27
M. Won, A. Ferraro, D. Bogdanov, and X. Serra, “Evaluation of CNN-based Automatic Music Tagging Models,” in Proc. of 17th Sound and Music Computing, 2020.
- 28
S. Ioffe and C. Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” in Proc. of the 32nd International Conference on Machine Learning, ICML. JMLR, 2015, pp. 448–456.
- 29
V. Nair and G. E. Hinton, “Rectified Linear Units Improve Restricted Boltzmann Machines,” in Proc. of the 27th International Conference on Machine Learning, ICML. Omnipress, 2010, pp. 807—-814.
- 30
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” in Proc. of the 3rd International Conference on Learning Representations, ICLR, 2015.
- 31
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 32
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 33
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 34
T. Fel, A. M. Picard, L. Bethune, T. Boissin, D. Vigouroux, J. Colin, R. Cad´ ene, and T. Serre, “CRAFT: concept` recursive activation factorization for explainability,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 2023, pp. 2711–2721.
- 35
J. D. Chang, J. L. Boyd-Graber, S. Gerrish, C. Wang, and D. M. Blei, “Reading Tea Leaves: How Humans Interpret
Topic Models,” in Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems 2009. Proceedings of a meeting held 7-10 December 2009, Vancouver, British Columbia, Canada. Curran Associates, Inc., 2009, pp. 288–296.
- 36
Leiner, Dominik J, “SoSci Survey (Version 3.5.01) [Computer software].” [Online]. Available: https://www.soscisurvey.de
- 37
R. Panda, R. Malheiro, and R. P. Paiva, “Musical Texture and Expressivity Features for Music Emotion Recognition,” in Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, September 23-27, 2018, 2018, pp. 383–391.
R. Panda, R. Malheiro, and R. P. Paiva, “Novel Audio Features for Music Emotion Recognition,” IEEE Trans. Affect. Comput., vol. 11, no. 4, pp. 614–626, 2020.
- 38
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 39
T. Eerola, “Are the Emotions Expressed in Music Genre-specific? An Audio-based Evaluation of Datasets Spanning Classical, Film, Pop and Mixed Genres,” Journal of New Music Research, vol. 40, no. 4, pp. 349–366, 2011.
- 40
J. H. Zar, “Spearman Rank Correlation,” Encyclopedia of Biostatistics, vol. 7, 2005.
- 41
M. Won, A. Ferraro, D. Bogdanov, and X. Serra, “Evaluation of CNN-based Automatic Music Tagging Models,” in Proc. of 17th Sound and Music Computing, 2020.
- 42
K. Koutini, J. Schluter, H. Eghbal-zadeh, and G. Widmer, “Efficient Training of Audio Transformers with Patchout,” in¨ Interspeech 2022, 23rd Annual Conference of the International Speech Communication Association, Incheon, Korea, 18-22 September 2022. ISCA, 2022, pp. 2753–2757.

Verena Szojak & Verena Praher
Verena Szojak is studying Artificial Intelligence and is currently completing her master's degree at JKU Linz. In her bachelor's thesis, she investigated approaches to overcome the limitations of concept-based explanations for an acoustic scene classifier.
Verena Praher is a Data Scientist with a background in Machine Learning, Explainable Artificial Intelligence and Sound Processing. During her PhD studies at the Institute of Computational Perception at JKU Linz, she focused on making explanations for deep models in Music Information Retrieval understandable for humans.
Article topics
Article translations are machine translated and proofread.
Artikel von Verena Szojak, Verena Praher
// Similar articles


