 Verena Szojak, Verena Praher
Verena Szojak, Verena Praher  Verena Praher
Verena Praher 
18 Minuten
Ein Einblick in erklärbare KI
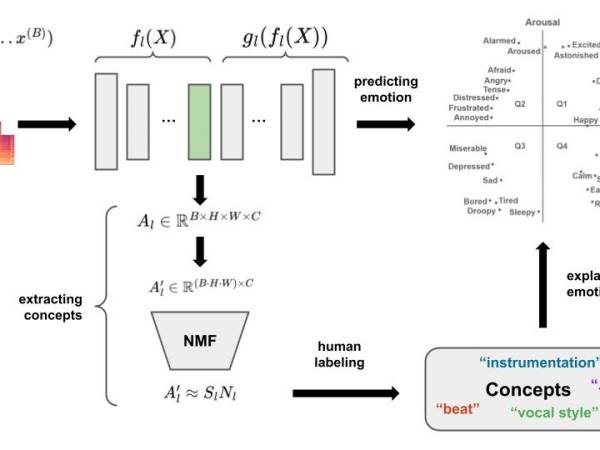
Figure 1: The upper part schematically shows the architecture for predicting emotion. The upper right part shows emotion quadrants in valence-arousal space, with indicative positioning of various emotion words. The lower part shows how concepts of an arbitrary layer l are extracted and labeled by humans to later explain the emotion predictions.
Deep AI-Modellarchitekturen haben die Modellleistung drastisch erhöht1. Mit zunehmender Komplexität des Modells wird jedoch nicht verstanden, wie ein Ergebnis zustande kommt.2, daher werden diese Modelle oft als "Black Boxes" bezeichnet. Für die Nutzer und Entwickler von Modellen ist es wichtig, Licht in diese "Black Boxes" zu bringen: Die Nutzer müssen den Modellentscheidungen vertrauen können3. Ein Modell, das mit einer großen Menge an Daten angelernt wurde, die möglicherweise menschliche Verzerrungen oder falsche Korrelationen enthalten, die sich dann in Entscheidungen niederschlagen4. Entwickler brauchen ein tiefes Verständnis, um Modelle zu verbessern5.
Um Modelle besser interpretierbar zu machen, wurden verschiedene Methoden der erklärbaren KI (XAI) eingeführt. Man unterscheidet zwischen ante-hoc (Training eines erklärbaren Modells) und post-hoc (Erklärung eines vortrainierten Modells), modellspezifisch (XAI-Methode funktioniert für eine Modellklasse, z. B. CNNs) und modellunabhängig (XAI-Methode funktioniert für alle Arten von Modellen), lokalen Erklärungen (Erklärung einer Probe) und globalen Erklärungen (Erklärung eines Modells, einer Klasse oder einer Teilmenge von Proben)6. Für einen tieferen Einblick in diese verschiedenen Methoden empfehlen wir folgende Seiten Interpretable Machine Learning: A Guide for Making Black Box Models Explainable.
Ein Ansatz sind konzeptbasierte Erklärungen, die auf hoher Ebene menschenfreundliche Erklärungen in Form von Konzepten bieten. "Ein Konzept kann eine beliebige Abstraktion sein, wie z. B. eine Farbe, ein Objekt oder sogar eine Idee.7 und "aus einzelnen Fällen verallgemeinert wird".8. Für unser MER-Modell könnten sich solche übergeordneten Verallgemeinerungen auf musikalische Merkmale beziehen, z. B. "Instrumentierung", "Beat", "Gesangsstil" usw.
Ziel dieses Artikels ist es, die Nachteile einer Methode zu beheben, die Konzepte ohne Vorwissen darüber extrahiert, was ein Konzept sein könnte, und mehr Erkenntnisse über gelernte Konzepte zu gewinnen. Dies wird uns näher daran bringen, den Nutzern hochrangige, für den Menschen verständliche Erklärungen zu liefern. Wir werden dies im Zusammenhang mit einer speziellen Aufgabe des Music Information Retrieval (MIR) untersuchen - der Musik-Emotionserkennung (MER) aus Audio.
Ein Modell anhand von Konzepten erklären
Zunächst müssen wir Konzepte aus unserem Modell extrahieren. Konzeptaktivierungsvektoren (CAVs) stellen diese "Konzepte" im Raum der Aktivierungskarte einer Modellschicht dar9. Dann können wir diese Konzepte nutzen, um ein tieferes Verständnis dafür zu bekommen, was unser Modell gelernt hat, um die verschiedenen Musikemotionen zu klassifizieren.
Gewinnung von Konzepten aus einem Modell
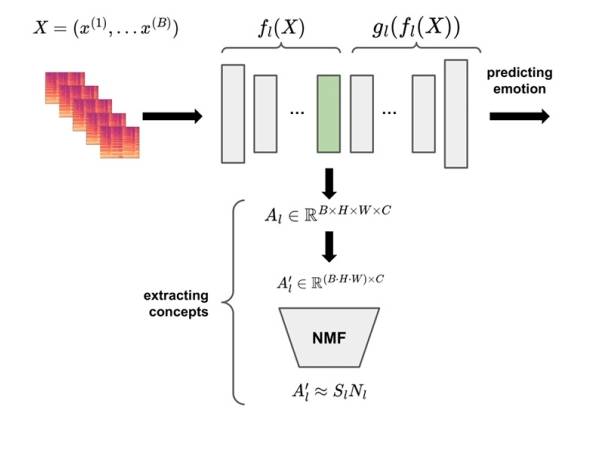
Figure 2: Extracting concepts of an arbitrary layer l.
Wir stützen uns bei der Erklärung auf die Arbeit von Zhang et al. 10 und Kim et al. 11. Die Vorhersage Y = m(X) für ein trainiertes Faltungsmodell m und Eingabeaudios X kann in jeder Schicht l in zwei Teile aufgeteilt werden: Y = m(X) = gl(fl(X)). fl(X) berechnet Aktivierungen Al ∈ RB×H×W×C, wobei B die Anzahl der Samples im Batch ist, H und W die Höhe und Breite der Aktivierungskarte sind und C die Anzahl der Kanäle ist. gl(Al) berechnet dann Y (d. h. gl repräsentiert den Teil des Netzwerks „oberhalb” der Schicht l und setzt den Vorwärtsdurchlauf fort). Um Konzeptaktivierungsvektoren (CAVs) für eine interessierende Schicht l zu erhalten, verwenden wir die nicht-negative Matrixfaktorisierung (NMF)12. Dieser Algorithmus lernt, eine nicht-negative Matrix durch zwei kleinere nicht-negative Matrizen darzustellen. Eine der kleineren Matrizen enthält die Konzepte und die andere ist die Kodierung, die die Informationen darüber enthält, wie die Konzepte kombiniert werden sollten. Folglich kann die NMF als Lernen eines Konzeptwörterbuchs betrachtet werden. Eine intuitive Visualisierung wird hier bereitgestellt.
Wir verwenden NMF, um nicht-negative CAVs (NCAVs) für eine bestimmte Modellebene l zu erhalten, indem wir die folgenden Schritte durchführen:

Figure 3
Gewünschte Konzepteigenschaften
In den letzten Jahren hat die Bewertung von XAI-Methoden im Hinblick auf gewünschte Eigenschaften von Konzepten an Bedeutung gewonnen. In der Literatur werden Eigenschaften wie Kohärenz, Bedeutsamkeit und Wichtigkeit genannt13, Interpretierbarkeit und Wiedergabetreue14,15. Bei dieser Arbeit werden wir uns auf Kohärenz und Sinnhaftigkeit konzentrieren. Konzeptbasierte Erklärungen sind von vornherein besser interpretierbar als andere Arten von Erklärungen16.
Wir legen fest, dass Konzepte zur Erklärung von Modellen in MIR verwendet werden sollten:
- kohärent: Beispiele für ein Konzept sollten sich in ihrer Wahrnehmung ähneln und sich von anderen Beispielen unterscheiden.17;
- bedeutungsvoll: verschiedene Menschen sollten Beispielen desselben Konzepts ähnliche Bedeutungen zuweisen18;
Bewertungsmetriken für Konzepte
Mit den resultierenden drei Matrizen Sl, Nl, A′l können wir mehrere Eigenschaften berechnen. Für detailliertere Informationen verweisen wir auf unser Paper.
Durchschnittliche Konzeptpräsenz: Diese Metrik berechnet eine Punktzahl, die sich auf die Stärke eines Konzepts in einer Stichprobe bezieht19,20. Anhand dieser Punktzahl werden wir die Beispiele für jedes Konzept einstufen.
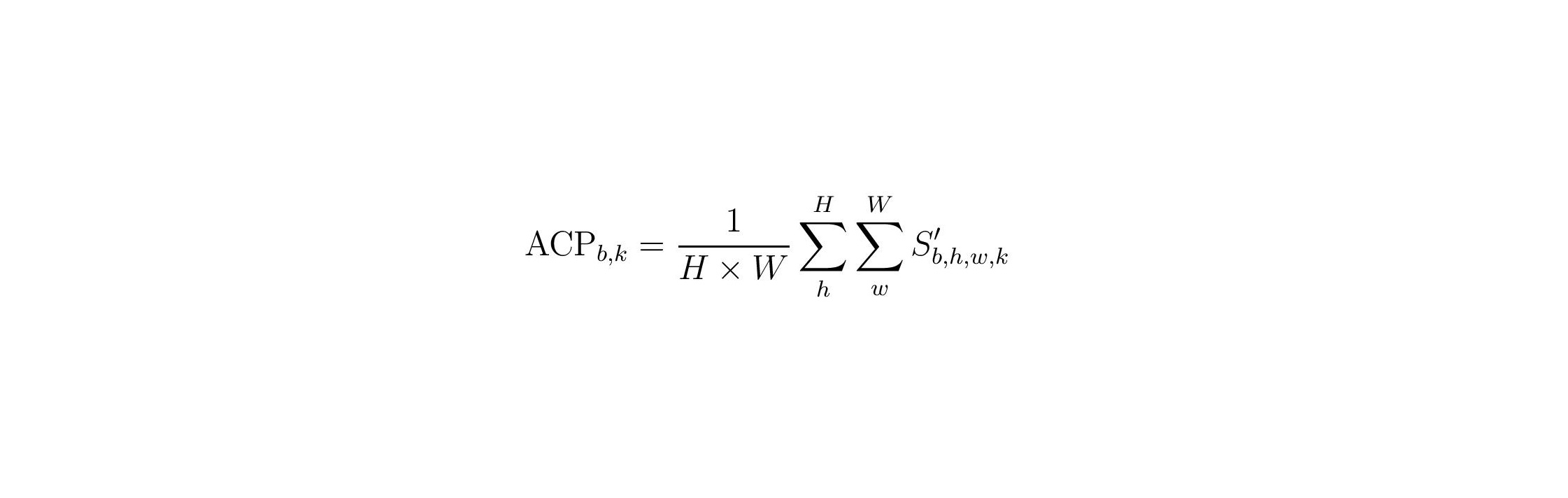
Figure 4
Lokale und globale Erklärungen: Um zu messen, wie relevant ein Konzept k in Schicht l (nlk bezeichnet den entsprechenden CAV) für die Vorhersage einer bestimmten Klasse q für ein einzelnes Eingabebeispiel ist (lokale Erklärung), können wir die konzeptionelle Sensitivität SENSk,l,q verwenden. 21.
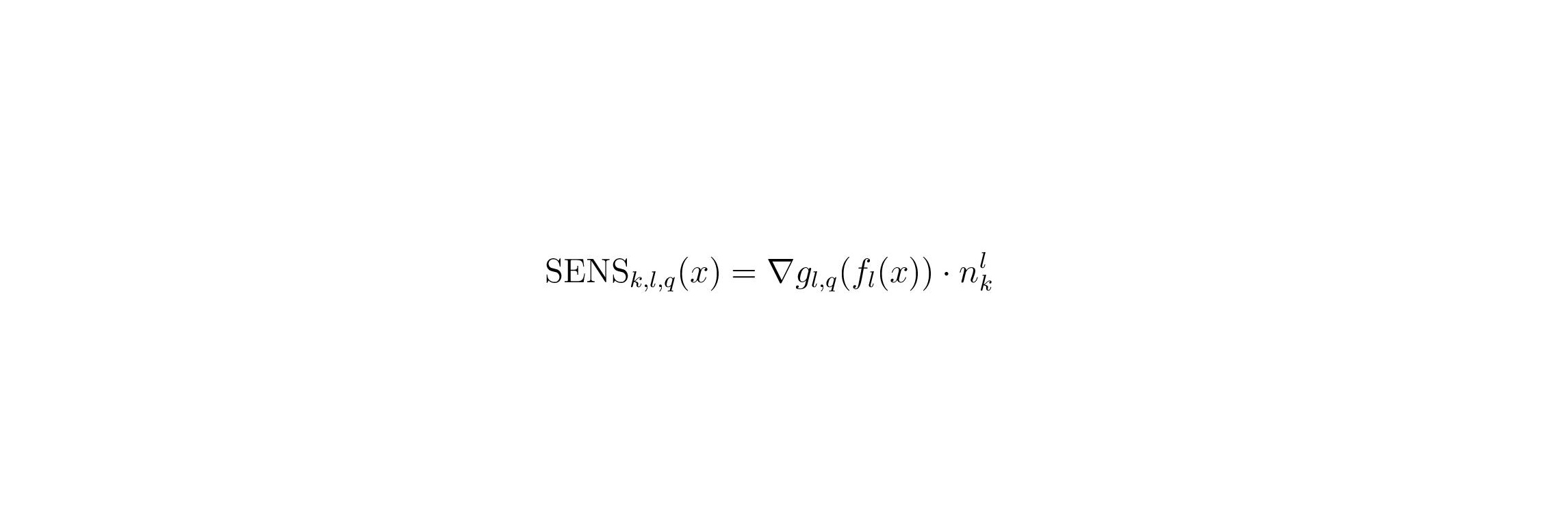
Figure 5
Um eine globale Erklärung zu erhalten, d. h. um die Frage zu beantworten, welches Konzept für die Vorhersage einer bestimmten Klasse im Allgemeinen relevant ist, können wir die CAV-Scores berechnen: Wir nehmen eine Reihe von Beispielen, die zu der interessierenden Klasse gehören, und berechnen den Anteil der Beispiele mit positiver konzeptueller Sensitivität22.
Vorhersage von Emotionen in der Musik
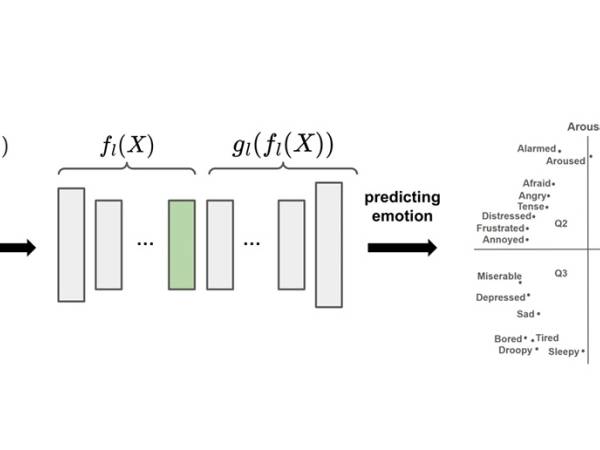
Figure 6: Architecture for predicting emotion from given spectrograms.
Wir haben alle Voraussetzungen, um Erklärungen aus einem Modell zu erhalten. Jetzt brauchen wir ein Modell, das wir analysieren können. In diesem Abschnitt beschreiben wir den Datensatz, die Modellarchitektur und den Trainingsaufbau für unser Modell, das die eingegebenen Audios in eine Reihe von diskreten Emotionsklassen klassifiziert.
4Q-Audio-Emotionen-Datensatz
Panda et al.23, 24 veröffentlichte den "4Q Audio Emotion Dataset" mit einer Vielzahl von Standard- und neuartigen Audiomerkmalen für MER. Er enthält Audioschnipsel und 1714 Audio-Features für 900 Musikstücke, die ein breites Spektrum an Musikstilen abdecken. Jedes Stück ist in einen der vier Quadranten von Russell's25 Valenz-Arousal-Raum (225 Hörproben pro Quadrant). Diese Quadranten (siehe den oberen rechten Teil von Abbildung 6) werden im Allgemeinen mit vier Grundemotionen gleichgesetzt: Glück/Überschwang (Q1), Angst (Q2), Depression (Q3) und Zufriedenheit (Q4). Die vier Quadrantenbezeichnungen dienen als diskrete Zielklassen für unser Emotionserkennungsmodell.
Die 1714 Merkmale bestehen aus 898 "Standard"-Deskriptoren (z. B. Nulldurchgangsrate, niedrige Energierate usw.), die mit verschiedenen Toolboxen berechnet wurden, und 816 "neuartigen" Merkmalen (einschließlich, aber nicht beschränkt auf melodische, rhythmische, musikalische Textur- und Ausdrucksmerkmale). Weitere Einzelheiten finden Sie in den Papieren, die diesen Datensatz vorstellen: Musical Texture and Expressivity Features for Music Emotion Recognition, Novel Audio Features for Music Emotion Recognition.
Dieser Datensatz dient zwei Zwecken: (1) die Audiodaten werden zum Trainieren unseres voll gefalteten MER-Modells verwendet und (2) die bereitgestellten Audiomerkmale werden zur Kennzeichnung unserer extrahierten Konzepte verwendet.
Modell zur Erkennung von Musik-Emotionen
Für das Training eines End-to-End MER-Modells basiert unsere Implementierung auf einem vollständig faltbaren NN (FCN)26, 27. Our model consists of 5 convolutional layers (with 32, 64, 64, 64 and 32 channels), each followed by BatchNorm28, ein ReLU 29 um die Nicht-Negativität der Aktivierungen und das maximale Pooling zu gewährleisten. Auf die Faltungsschichten folgen eine lineare Schicht, Dropout (p=0,5) und eine Softmax-Schicht. Diese Architektur kann Audio-Input in voller Länge verarbeiten (30 Sekunden in unseren Experimenten), was nützlich ist, da die Audio-Merkmale, mit denen wir vergleichen, auf den vollständigen Audio-Spektrogrammen berechnet werden.
Wir führten eine Rastersuche durch, um die optimalen Hyperparameter zu bestimmen. Die höchste Validierungsgenauigkeit wurde mit einem Modell erzielt, das 100 Epochen lang mit Adam30 mit einer Lernrate von 5 ∗ 10−4 und einer Batchgröße von 8. Wir haben das beste Modell zehnmal neu trainiert und berichten über die Leistung des Testsatzes in Bezug auf die Genauigkeit: 0,734 ± 0,014.
Musik Emotionen erklären
Mit dem trainierten Musik-Emotionserkennungsmodell und dem skizzierten Erklärbarkeitsansatz berechnen wir CAVs unter Verwendung von Trainingsdaten für jede der 5 Faltungsschichten unseres Modells und analysieren sie im Hinblick auf die gewünschten Eigenschaften: Kohärenz und Bedeutsamkeit.
Hörversuch
Wir haben ein Hörexperiment entworfen, um zu untersuchen, ob die extrahierten Konzepte kohärent sind (Beispiele eines Konzepts sollten sich in der Wahrnehmung ähneln und sich von anderen Beispielen unterscheiden31) und sinnvoll (verschiedene Menschen sollten den Beispielen desselben Begriffs ähnliche Bedeutungen zuweisen 32). Was die Kohärenz betrifft, so lassen wir uns von neueren Arbeiten inspirieren, die Experimente zur Erkennung von Eindringlingen durchgeführt haben33, 34, inspired by 35. Den Teilnehmern wird eine Reihe von Beispielen vorgelegt, von denen alle bis auf eines zum selben Konzept gehören. Sie werden gebeten, dasjenige zu identifizieren, das nicht dazu gehört (als Eindringling bezeichnet). Um die Aussagekraft zu testen, fragen wir die Teilnehmer nach den Ähnlichkeiten zwischen den Nicht-Eindringlingen. Dazu haben wir das Tool SosciSurvey36 um den Online-Fragebogen zu erstellen.
Den Teilnehmern werden 10 Sätze (2 pro Modellschicht) von jeweils 4 Hörbeispielen präsentiert. Jedes Set besteht aus den 3 Audiobeispielen mit dem höchsten ACP für ein Konzept von Interesse und einem Eindringling (der den niedrigsten ACP für das ausgewählte Konzept hat).
Für jedes Audiobeispiel wird ein 10-Sekunden-Schnipsel genommen (der den höchsten/niedrigsten ACP für dieses Stück hat). Für jeden Satz stellen wir die folgenden drei Fragen:
- Welches der folgenden Musikstücke unterscheidet sich von den anderen drei Stücken?
- Wie sicher sind Sie sich, dass sich das von Ihnen ausgewählte Stück von den anderen unterscheidet? [Vier Auswahlfelder von „Ich bin mir sehr sicher“ bis „Ich musste raten“.]
- Bitte beschreiben Sie die gemeinsamen Merkmale der drei ähnlichen Stücke. Was macht diese drei Stücke einander ähnlich?
Für die 4 CAVs der ersten Modellebene stellen wir die Hörproben zur Verfügung. Diese werden von Panda et al. (2018) bereitgestellt. 37 und kann here gefunden werden. Können Sie den Eindringling erkennen?
| Konzept 1 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Konzept 2 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Konzept 3 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
| Konzept 4 | |
Audio file
©
| Audio file
©
|
Audio file
©
| Audio file
©
|
Antworten: Ex3; Ex2; Ex3; Ex1
Im Folgenden bezieht sich "Item" auf ein Set bestehend aus 4 Audios (insgesamt 40 Sekunden Audio) und den dazugehörigen 3 Fragen.
Gesamtstatistik
Um die Variabilität unter den Teilnehmern zu verringern, baten wir Personen zwischen 25 und 35 Jahren, die mindestens ein Instrument spielen können, um ihre Teilnahme. Um die Antworten der Teilnehmer nicht zu verzerren, wussten sie nicht, dass es sich bei der Vorhersageaufgabe um Musikemotionen handelte. Wir rekrutierten 13 Teilnehmer. Obwohl wir mit Schlussfolgerungen aus dieser kleinen Zahl vorsichtig sein müssen, ermöglicht sie uns eine qualitative Analyse, indem wir Freitextfragen stellen und auswerten. Der Median der Zeit, die ein Teilnehmer für die Bewertung aller 10 Items (10 × 4 × 10 Sekunden = 6,67 Minuten Audio) benötigte, betrug 22,15 Minuten (IQR = 14,85, 27,5).
Extrahierte Konzepte sind kohärent
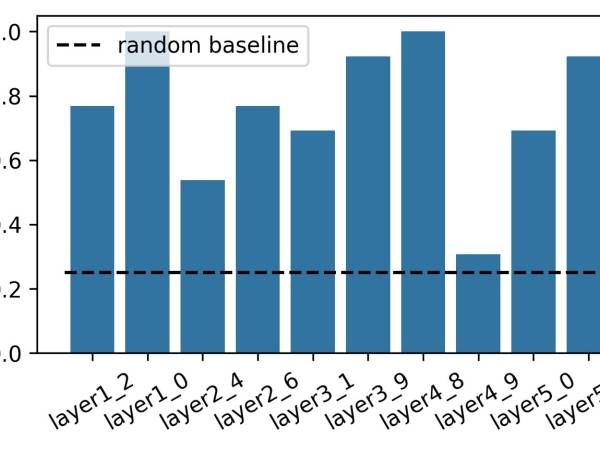
Figure 7: This figure shows the intruder detection rate for each of the 10 items in the questionnaire labeled by the corresponding layer and CAV.
Die Teilnehmer identifizierten 76,15 % (±21,89) der Eindringlinge richtig (zwischen 30,77 % und 100 % pro Set). Die Erkennungsrate der Eindringlinge pro Konzept ist in Abbildung 7 dargestellt.
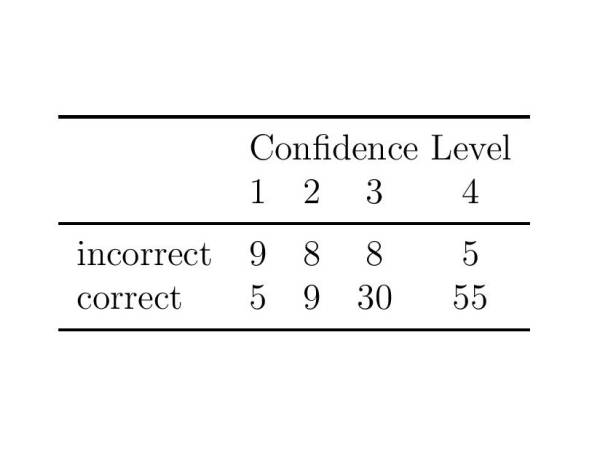
Figure 8: Reported confidence scores for correctly and in correctly detected intruders. The confidence scores range from 1 (“I had to guess”) to 4 (“I am very confident.”).
Die Teilnehmer wurden auch gebeten, ihren Vertrauensgrad anzugeben. Die Ergebnisse sind in Abbildung 8 zusammengefasst. Die Zuhörer waren sehr zuversichtlich, was ihre richtige Wahl anging, und wählten häufiger "Ich musste raten", wenn sie ein falsches Beispiel als Eindringling auswählten.
Diese Ergebnisse lassen den Schluss zu, dass die meisten der Konzepte, die wir unseren Teilnehmern vorstellten, kohärent sind, d. h., dass die Beispiele, die zu dem Konzept gehören, sich in der Wahrnehmung ähneln, während sie sich von anderen Beispielen unterscheiden38.
Extrahierte Konzepte sind aussagekräftig
Um zu beurteilen, ob die extrahierten Konzepte aussagekräftig sind, untersuchen wir die Antworten der Teilnehmer auf Frage 3 (Bitte beschreiben Sie die gemeinsamen Merkmale der drei ähnlichen Stücke. Was macht diese drei Stücke einander ähnlich?).
Wir betrachten alle Antworten, die für zwei der Aufgaben gegeben wurden, eine, bei der alle Teilnehmer den richtigen Eindringling erkannten (layer4_8), und die schwierigste - mit nur 30,77% richtigen Antworten (layer4_9).
| Layer 4, Konzept 8 | ||
Audio file
©
| Audio file
©
| Audio file
©
|
| Layer 4, Konzept 9 | ||
Audio file
©
| Audio file
©
| Audio file
©
|
Für beide Items haben wir (manuell) Begriffe extrahiert, die dazu dienten, zu beschreiben, was der Teilnehmer für die drei ähnlichen Audioschnipsel hielt. Die extrahierten Begriffe für beide Items sind visualisiert:

Figure 9: Word clouds summarising the descriptions that participants gave for Layer 4 CAV8: all terms center around the notion of ‘genre’.

Figure 10: Word clouds summarising the descriptions that participants gave for Layer4 CAV9: no clear semantic focus can be identified.
Die Antworten für den Fall, in dem das Konzept klar erfasst wurde, mit 100 % Zustimmung zum Eindringling, Schicht4_8, haben eine klare musikalische Bedeutung, die sich im Wesentlichen um den Begriff des Genres dreht. Dies stimmt mit den Beobachtungen von Eerola überein39 über die Bedeutung des Genres für die Vorhersage von Emotionen und legt nahe, dass das Genre generell bei der Benennung von Konzepten in diesem Zusammenhang berücksichtigt werden sollte. Für den Fall, dass die Teilnehmer Schwierigkeiten hatten, den Eindringling zu erkennen (Layer4_9), ist kein semantischer Fokus zu erwarten, da die Genauigkeit der Teilnehmer bei der Identifizierung des Eindringlings kaum über dem Ausgangswert lag.
Um die Aussagekraft von CAVs weiter zu bewerten, untersuchen wir die aggregierten CAV-Werte für Ebene 1 (Audios sind oben angegeben), um zu beurteilen, ob CAVs einen positiven Beitrag zu einer der vier Klassen/Emotionsquadranten leisten. Hier verwenden wir die konzeptionelle Sensitivität SENSk,l,q(x) und zeigen CAVs, die für mindestens die Hälfte der Samples eines bestimmten Emotionsquadranten einen positiven Beitrag leisten.

Figure 11: Abstracted CAV Scores for layer1. Scores ≥ 0.5 appear as ‘+’, values < 0.5 as ‘o’.
Konzentrieren wir uns auf die Konzepte, die Teil des Hörversuchs waren (CAV0, CAV2), da wir für diese Konzepte menschliche Annotationen haben.
- CAV0, das hohe CAV-Werte für die Emotionsklassen Q1 (0,57) und insbesondere Q2 (0,70) aufweist, wird als "energisch", "rasant" und "laut" beschrieben, und Aspekte wie "aggressiver Gesang", "Gesangsstil", "Gitarre mit Verzerrung" und "Schlagzeug" werden hervorgehoben.
- CAV2, das einen hohen Wert für Q1 (0,77) hat, wird als "harmonisch", "melodisch" und "romantisch" beschrieben, und die Teilnehmer erwähnten Aspekte wie "melodischer Gesang" und "der Gesang ist sauber und fröhlich".
Diese Begriffscharakterisierungen (die wir indirekt über unsere Hörstudie erhalten haben) sind intuitiv mit den Emotionen vereinbar, die die jeweiligen Emotionsquadranten repräsentieren (Q1 wird im Allgemeinen mit "glücklich" und "aufgeregt" assoziiert, Q2 mit Emotionen wie "angespannt", "wütend", "verzweifelt").
Schlussfolgerung
In diesem Artikel haben wir einen Ansatz zur Extraktion von Konzepten aus einem vortrainierten Modell beschrieben und ihn auf ein Modell zur Erkennung von Emotionen in tiefer Musik angewendet, um die gewünschten Konzepteigenschaften zu untersuchen. Wir haben ein Hörexperiment durchgeführt, das gezeigt hat, dass die extrahierten Konzepte kohärent und sinnvoll sind.
Es gibt noch Raum für zukünftige Arbeit. Ohne menschliche Beschriftung haben die extrahierten Konzepte keine Bedeutung. Die manuelle Beschriftung kann zeitaufwändig werden, wenn mehrere Konzepte für alle Schichten extrahiert werden. Um zu testen, ob wir die extrahierten Konzepte, die die Vorhersagen auf hoher Ebene erklären, automatisch beschriften und die relevantesten Bezeichnungen erhalten können, schlagen wir in unserem Papier einen Ansatz vor, der die Spearman-Rangkorrelation40 und ACP für Deskriptoren der unteren und mittleren Ebene. Während wir den Konzepten automatisch eine Bedeutung auf niedriger und mittlerer Ebene zuweisen können, hat der Hörversuch gezeigt, dass dies nicht das ist, was Menschen verwenden, um zusammenhängende Beispiele zu beschreiben - konzeptbasierte Erklärungen in MIR könnten mehrere Ebenen von Etiketten erfordern, die jedem Konzept zugewiesen werden; und wir müssen möglicherweise automatische Musik-Tagging-Modelle einbeziehen41, 42 die reichhaltigere Bezeichnungen liefern können, um den Begriffen Bedeutung zu verleihen.
V. Praher, V. Szojak und G. Widmer, “Concept-based Explanations for Music Emotion Recognition“, in Proceedings of the 22nd Sound and Music Computing Conference (SMC2025), Graz, July 2025, Graz, Austria, Juli 2025, S. 234–241. doi: 10.5281/zenodo.15837275.
- 1
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, pp. 436–44, 05 2015.
- 2
W. Samek and K.-R. Muller,¨ Towards Explainable Artificial Intelligence. Cham: Springer International Publishing, 2019, pp. 5–22. [Online]. Available: https://doi.org/10.1007/978-3-030-28954-6 1
- 3
R. Fong and A. Vedaldi, Explanations for Attributing Deep Neural Network Predictions. Cham: Springer International Publishing, 2019, pp. 149–167. [Online]. Available: https://doi.org/10.1007/978-3-030-28954-6 8
- 4
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, and D. Pedreschi, “A survey of methods for explaining black box models,” ACM Comput. Surv., vol. 51, no. 5, Aug. 2018. [Online]. Available: https://doi.org/10.1145/3236009
- 5
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in Computer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 818–833.
- 6
C. Molnar, Interpretable Machine Learning, 3rd ed., 2025. [Online]. Available: https://christophm.github.io/ interpretable-ml-book
- 7
C. Molnar, Interpretable Machine Learning, 3rd ed., 2025. [Online]. Available: https://christophm.github.io/ interpretable-ml-book
- 8
“concept,” https://www.merriam-webster.com/dictionary/concept, accessed: 2025-07-11
- 9
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 10
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 11
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 12
D. D. Lee and H. S. Seung, “Learning the Parts of Objects by Non-negative Matrix Factorization,” Nature, vol. 401, no. 6755, pp. 788–791, Oct 1999.
- 13
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 14
M. T. Ribeiro, S. Singh, and C. Guestrin, “”Why Should I Trust You?”: Explaining the Predictions of Any Classifier,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016. ACM, 2016, pp. 1135–1144.
- 15
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 16
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 17
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 18
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 19
R. Zhang, P. Madumal, T. Miller, K. A. Ehinger, and B. I. P. Rubinstein, “Invertible Concept-based Explanations for CNN Models with Non-negative Concept Activation Vectors,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021. AAAI Press, 2021, pp. 11682–11690.
- 20
F. Foscarin, K. Hoedt, V. Praher, A. Flexer, and G. Widmer, “Concept-Based Techniques for ”Musicologist-Friendly” Explanations in Deep Music Classifiers,” in Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022, Bengaluru, India, December 4-8, 2022, 2022, pp. 876–883.
- 21
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 22
B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viegas, and R. Sayres, “Interpretability Beyond Feature´ Attribution: Quantitative Testing with Concept Activation Vectors (TCAV),” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, July 10-15, 2018, vol. 80. PMLR, 2018, pp. 2673–2682.
- 23
R. Panda, R. Malheiro, and R. P. Paiva, “Musical Texture and Expressivity Features for Music Emotion Recognition,” in Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, September 23-27, 2018, 2018, pp. 383–391.
- 24
R. Panda, R. Malheiro, and R. P. Paiva, “Novel Audio Features for Music Emotion Recognition,” IEEE Trans. Affect. Comput., vol. 11, no. 4, pp. 614–626, 2020.
- 25
J. A. Russell, “A Circumplex Model of Affect,” Journal of personality and social psychology, vol. 39, no. 6, p. 1161, 1980.
- 26
K. Choi, G. Fazekas, and M. B. Sandler, “Automatic Tagging Using Deep Convolutional Neural Networks,” in Proceedings of the 17th International Society for Music Information Retrieval Conference, ISMIR 2016, New York City, United States, August 7-11, 2016, 2016, pp. 805–811.
- 27
M. Won, A. Ferraro, D. Bogdanov, and X. Serra, “Evaluation of CNN-based Automatic Music Tagging Models,” in Proc. of 17th Sound and Music Computing, 2020.
- 28
S. Ioffe and C. Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” in Proc. of the 32nd International Conference on Machine Learning, ICML. JMLR, 2015, pp. 448–456.
- 29
V. Nair and G. E. Hinton, “Rectified Linear Units Improve Restricted Boltzmann Machines,” in Proc. of the 27th International Conference on Machine Learning, ICML. Omnipress, 2010, pp. 807—-814.
- 30
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” in Proc. of the 3rd International Conference on Learning Representations, ICLR, 2015.
- 31
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 32
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 33
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 34
T. Fel, A. M. Picard, L. Bethune, T. Boissin, D. Vigouroux, J. Colin, R. Cad´ ene, and T. Serre, “CRAFT: concept` recursive activation factorization for explainability,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 2023, pp. 2711–2721.
- 35
J. D. Chang, J. L. Boyd-Graber, S. Gerrish, C. Wang, and D. M. Blei, “Reading Tea Leaves: How Humans Interpret
Topic Models,” in Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems 2009. Proceedings of a meeting held 7-10 December 2009, Vancouver, British Columbia, Canada. Curran Associates, Inc., 2009, pp. 288–296.
- 36
Leiner, Dominik J, “SoSci Survey (Version 3.5.01) [Computer software].” [Online]. Available: https://www.soscisurvey.de
- 37
R. Panda, R. Malheiro, and R. P. Paiva, “Musical Texture and Expressivity Features for Music Emotion Recognition,” in Proceedings of the 19th International Society for Music Information Retrieval Conference, ISMIR 2018, Paris, France, September 23-27, 2018, 2018, pp. 383–391.
R. Panda, R. Malheiro, and R. P. Paiva, “Novel Audio Features for Music Emotion Recognition,” IEEE Trans. Affect. Comput., vol. 11, no. 4, pp. 614–626, 2020.
- 38
A. Ghorbani, J. Wexler, J. Y. Zou, and B. Kim, “Towards Automatic Concept-based Explanations,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 9273–9282.
- 39
T. Eerola, “Are the Emotions Expressed in Music Genre-specific? An Audio-based Evaluation of Datasets Spanning Classical, Film, Pop and Mixed Genres,” Journal of New Music Research, vol. 40, no. 4, pp. 349–366, 2011.
- 40
J. H. Zar, “Spearman Rank Correlation,” Encyclopedia of Biostatistics, vol. 7, 2005.
- 41
M. Won, A. Ferraro, D. Bogdanov, and X. Serra, “Evaluation of CNN-based Automatic Music Tagging Models,” in Proc. of 17th Sound and Music Computing, 2020.
- 42
K. Koutini, J. Schluter, H. Eghbal-zadeh, and G. Widmer, “Efficient Training of Audio Transformers with Patchout,” in¨ Interspeech 2022, 23rd Annual Conference of the International Speech Communication Association, Incheon, Korea, 18-22 September 2022. ISCA, 2022, pp. 2753–2757.

Verena Szojak & Verena Praher
Verena Szojak studiert Künstliche Intelligenz und absolviert derzeit ihr Masterstudium an der JKU Linz. In ihrer Bachelorarbeit untersuchte sie Ansätze zur Überwindung der Grenzen von konzeptbasierten Erklärungen für einen akustischen Szenenklassifikator.
Verena Praher ist Data Scientist mit einem Hintergrund in maschinellem Lernen, erklärbarer künstlicher Intelligenz und Klangverarbeitung. Während ihres Doktoratsstudiums am Institut für Computational Perception der JKU Linz konzentrierte sie sich darauf, Erklärungen für tiefe Modelle im Music Information Retrieval für Menschen verständlich zu machen.
Artikelthemen
Artikelübersetzungen erfolgen maschinell und redigiert.
// Ähnliche Artikel


