Sinan Bökesoy
Sinan Bökesoy 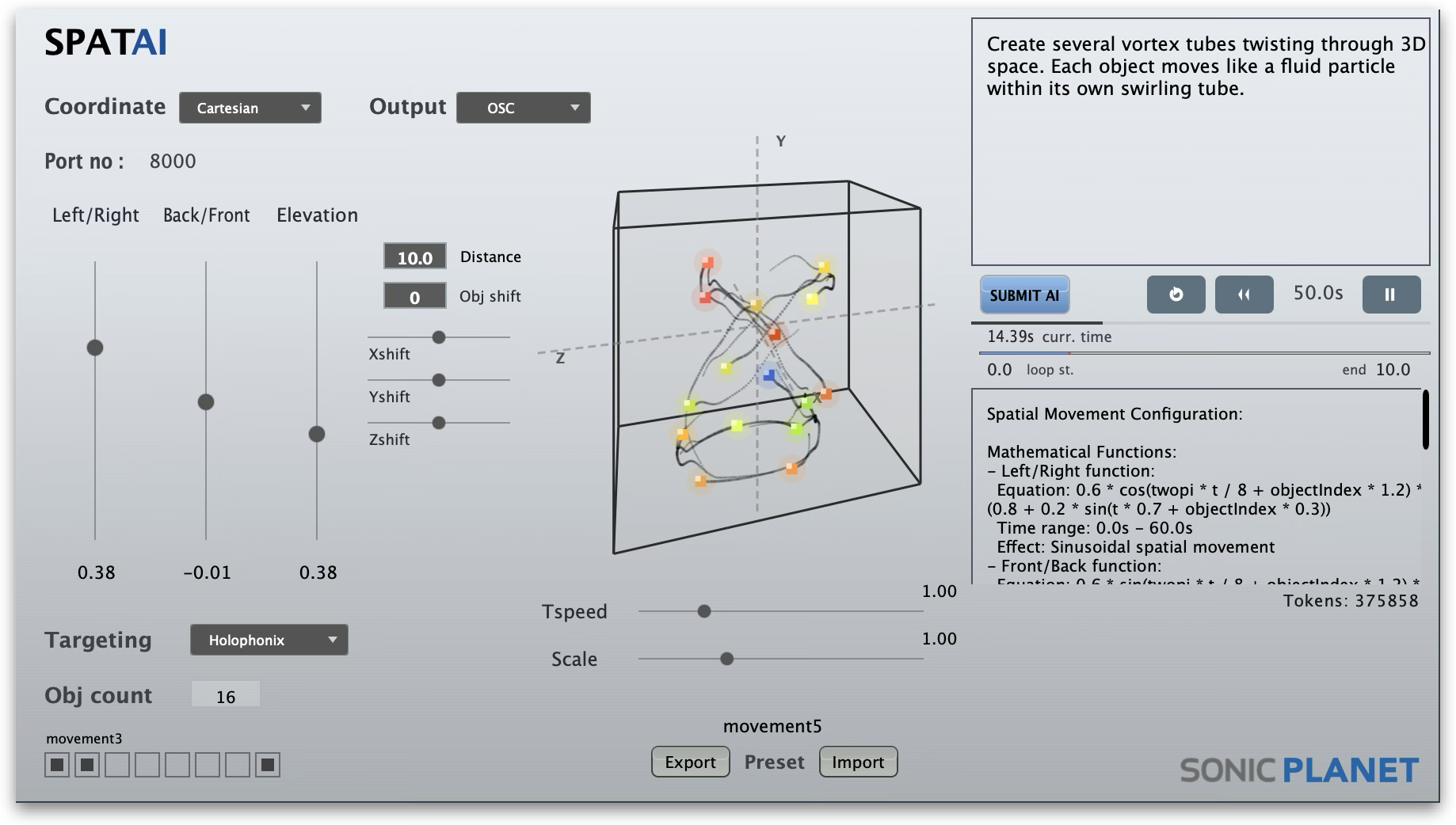
9 Minuten
Introduction: The Creative Bottleneck in 3D Space
The landscape of immersive audio is rapidly evolving. But while existing rendering engines have democratized 3D audio, the interface for movement remains tethered to rather less efficient paradigm. In the case of DAW workflow, creators are often forced into a technical, non-intuitive workflow: precise sliders for Left/Right, Front/Back, and Elevation.
When a composer wishes to move 8 objects in a coordinated "flock," they are faced with the daunting task of drawing separate automation curves by hand. Fortunately, the industry has seen the emergence of tools specifically dealing with movement design that communicate with the renderer, offering a better interface to handle panning trajectories.
We can summarize this workflow as an ecosystem consisting of three distinct pillars: a Spatial Renderer, an Object Movement Designer (OMD), and the DAW as the host.
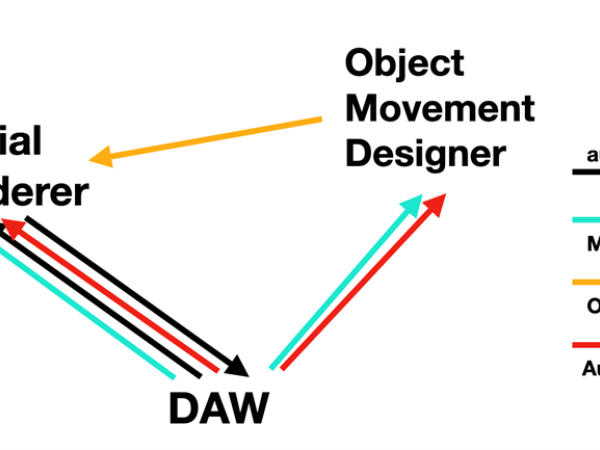
DAW: The host environment feeds the Spatial Renderer with audio material ranging from mono to various multi-channel configurations. It manipulates the parameters of both the Spatial Renderer and the OMD using MIDI control messages and standard parameter automation.
Spatial Renderer: This engine applies audio processing to the input material coming from the DAW to position each channel in 3D space. It receives object position data either from the DAW via parameter automation or, more dynamically, from the Object Movement Designer via OSC or MIDI. (Note: The Spatial Renderer must have a specific OSC implementation to accept external control ).
Object Movement Designer (OMD): This category of software allows the user to design trajectories for multiple objects simultaneously. It creates the dynamic scene for 3D audio by controlling the positioning of all active objects within it. It can receive parameter automation or MIDI control messages from the DAW, while simultaneously sending calculated position data in real-time to the Spatial Renderer.
The Paradigm Shift: Natural Language creating the Dynamic Scene
Movement trajectory design should not reduce the art of spatialization to mere data entry. SpatAI was conceived to dissolve this barrier, utilizing Large Language Models (LLMs) not as chatbots, but as specialized mathematical translators that bridge natural language commands with technical 3D audio engines.
This represents a fundamental shift in how we interact with acoustic scene. The user inputs a descriptive text prompt—for example, "create a 12-second spiral rising from each object”. And imagine that one can write this on any spoken language.
Previously, achieving such complex motion required the user to manually define parametric equations within the Object Movement Designer or chain together pre-defined functions to approximate the desired trajectory. The creative intent had to be manually translated into a performable equation—a labor-intensive process of micro-managing data rather than macro-managing sound.
In SpatAI, the AI interprets these semantic instructions and converts them into precise mathematical equations for motion. These equations are then executed in real-time on a timeline, generating coordinate data in either Cartesian (cubic space) or Polar (spherical) formats to match the destination renderer
Let us look at what is required to manually program a simple "upward spiral" that completes a rotation every 4 seconds over a 12-second duration.
In a Traditional Cartesian Workflow: The user must derive three separate functions to control the X (Left/Right), Y (Front/Back), and Z (Elevation) parameters. To achieve a perfect circle, they must use synchronized sinusoidal functions, and for the upward motion, a linear ramp.
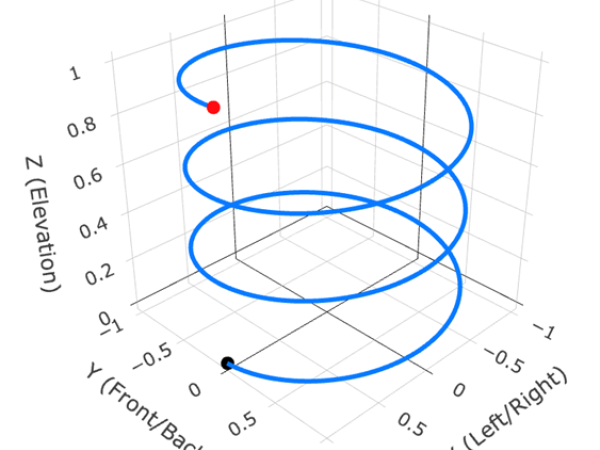
In a Polar/Spherical Workflow (e.g., for Ambisonics): The challenge shifts to angles. The user must calculate an azimuth that wraps continuously and an elevation that moves from the horizon (0∘) to the zenith (90∘).
The Semantic Solution: In SpatAI, this entire derivation process is bypassed. The user simply prompts:
Place objects 1 to 16 in positions from (0, -0.9, -0.3) to (0, 0.9, 0.7) and create a 12-second spiral rising from each of them.
The AI automatically generates the underlying math—such as
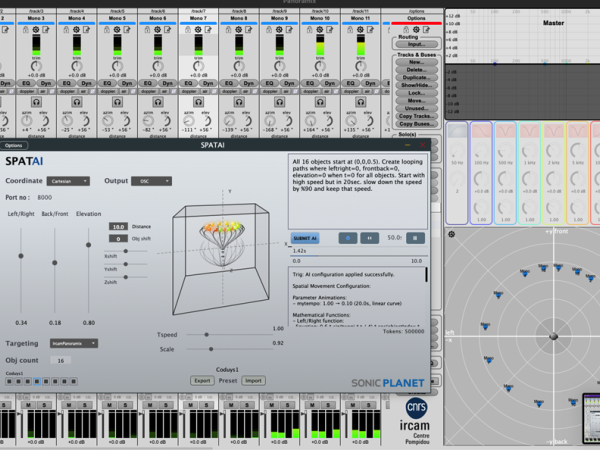
0.6 * sin(twopi * t / 4 + objectIndex * 0.3) — and maps it to the target's coordinate system, whether Cartesian or Polar. This allows the composer to think in gestures rather than trigonometry. Below you can see the objects in their calculated starting positions and then the spiral movement
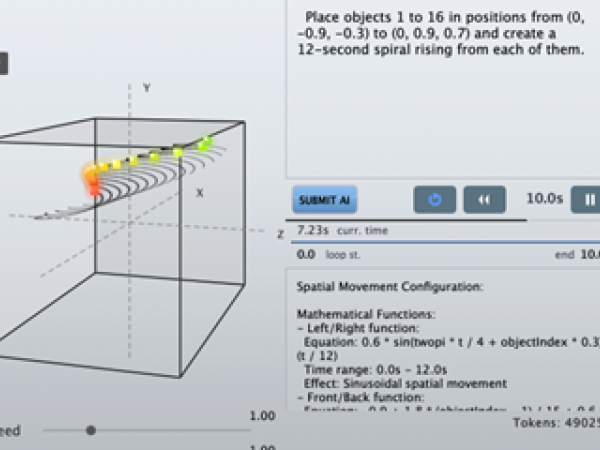
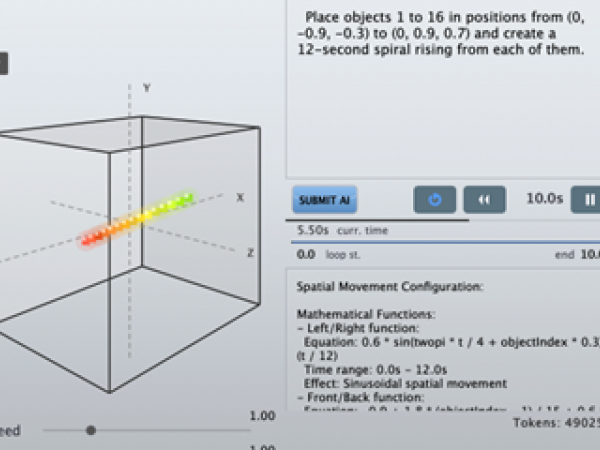
Below you can see the human readable description of the AI for the composed object movement. This is being applied to each object on the scene. The application receives this response and calculates the positions in real time while changing the “t” parameter from 0 to 12 in 12seconds.
Spatial Movement Configuration:
Mathematical Functions:
Left/Right function:Equation: 0.6 * sin(twopi * t / 4 + objectIndex * 0.3) * (t / 12)Time range: 0.0s - 12.0sEffect: Sinusoidal spatial movement
Front/Back function:Equation: -0.9 + 1.8 * (objectIndex - 1) / 15 + 0.6 * cos(twopi * t / 4 + objectIndex * 0.3) * (t / 12)Time range: 0.0s - 12.0sEffect: Cosine-based spatial movement
Elevation function:Equation: 0.3 + 0.4 * (objectIndex - 1) / 15 + 0.4 * (t / 12)Time range: 0.0s - 12.0sEffect: Custom mathematical spatial functionTimeline Duration: 12.0 seconds
The Human-in-the-Loop: Macro-Control as Performance
Once the AI has derived the mathematical equations for a scene, the software exposes a layer of Global Macro Controls. These controls act as real-time modifiers that sit between the algorithmic output and the final OSC/MIDI data stream, allowing the user to manipulate the generated results dynamically.
This architecture effectively shifts the user’s role from "drafter" (drawing lines) to "conductor" (shaping behavior).
1. Time Dilation (TSpeed): The TSpeed parameter allows for the elastic manipulation of the global timeline. The user can accelerate a slow, evolving texture into a chaotic swarm or decelerate a rapid gesture into a frozen, sculptural state. Because the underlying movement is defined by continuous mathematical functions rather than discrete keyframes, this time-stretching introduces no quantization artifacts—the resolution remains infinite regardless of speed.
2. Spatial Density and Offset (Scale & Shift): The Scale and Shift (X, Y, Z) parameters allow the user to recontextualize the AI’s output within the acoustic environment.
- Scale: Adjusts the expansion of the coordinate system. A user might prompt the AI for a "flocking behavior," then use the Scale slider to contract that flock into a tight, localized point source or expand it to encompass the entire immersive dome.
- Shift: Allows for the translation of the entire object group. A complex "chaotic attractor" generated at the center of the room can be grabbed and offset to the rear-left quadrant without breaking its internal motion logic.
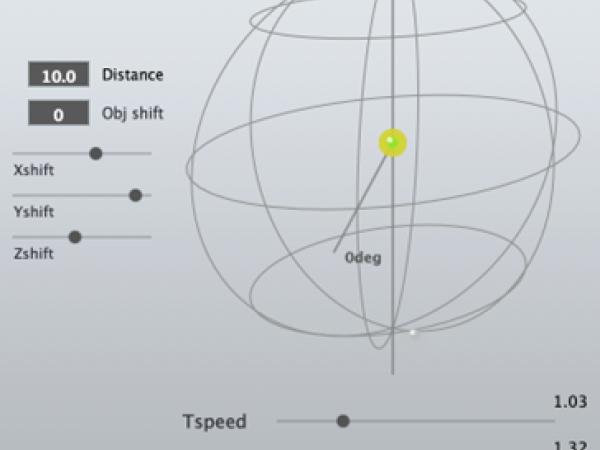
The Performative Ecosystem Crucially, these macro controls are fully automatable within the host DAW and all sliders can be controlled with external Midi controllers.
Interoperability and Expansion: The OSC Architecture
Because the software generates control data rather than audio signals, its utility is defined by its ability to communicate with the diverse array of rendering engines currently used in academic and professional contexts.
To achieve this, SpatAI functions as a polyglot control layer. It utilizes Open Sound Control (OSC) as its primary language, allowing it to decouple the "trajectory generation" from the "spatial rendering." This architecture allows the system to support both rigid industry standards and experimental, expandable setups.
Out of the box, SpatAI includes dedicated mapping profiles for some leading surround sound authoring environments. The system currently interfaces directly with:
- IEM MultiEncoder: (Graz) A standard for higher-order Ambisonics.
- Holophonix: (Amadeus) For wave field synthesis and object-based mixing.
- IRCAM Spat & Panoramix: The academic benchmarks for spatial signal processing.
- Yamaha AFC: For active field control in architectural acoustics.
When one of these targets is selected, SpatAI automatically handles the internal coordinate normalization—scaling the AI’s mathematical output to fit the specific requirements of the target engine (e.g., locking the radius to 1.0 for IEM’s spherical requirements, or mapping to specific Cartesian bounds for Holophonix).
The Expandable Structure: Generic Output However, the system is designed to be future-proof against the emergence of new renderers or custom research tools. Beyond the native presets, SpatAI offers a Generic OSC mode. This exposes a standardized address structure, allowing users to map SpatAI to custom Max/MSP patches, SuperCollider environments, or emerging VR engines.
- Cartesian Generic: Broadcasts combined XYZ messages in the format: /object/N/xyz FLOAT(x) FLOAT(y) FLOAT(z)
- Polar Generic: Broadcasts discrete spherical coordinates: /object/N/azim, /object/N/elev, and /object/N/dist
This open architecture ensures that the "Object Movement Designer" remains a distinct, flexible module within the studio ecosystem, capable of driving any destination that speaks the language of OSC. As the landscape of 3D audio evolves, the user’s movement algorithms remain valid, requiring only a change in destination port to address new rendering technologies.
LLM’s Token Economy: A Sustainable Model for Generative Tools
1. Running an LLM on your local machine:
Local LLMs are generally open-source models that can be downloaded and installed for free. Various models are available to run directly on a user’s desktop, with hardware requirements (RAM and GPU power) varying based on the model's parameter size. These models typically run in the background via host applications like Ollama or LM Studio. SpatAI accesses these local instances through the host application's local URL. The downside is that you need a compatible computer to run models such as with 8B parameters ( running on a GPU ) and considerable amount of RAM ( ideally minimum 16GB for a context size of 8192 tokens which is necessary for SPATAI ). The advantage is that the user does not consume any tokens, because the LLM runs on the current machine.
2. Running a Cloud based LLM:
When the user selects the “Cloud LLM”, SpatAI harnesses a cloud-based AI API in the frontier class (estimated in the hundreds of billions of parameters). As is the industry standard for models of this capability, the service operates on a token-based billing structure. The advantage is that the user does not require to obtain a powerful enough computer. But token consumption will be charges.
Integrating high-performance Large Language Models (LLMs) into desktop software introduces a unique economic challenge: every single inference carries a real-world computational cost. In the current SaaS landscape, the standard industry response has been the monthly subscription. However, for a specialized production tool like SpatAI—which a sound designer might use intensively for a week-long project and then leave idle for a month—a recurring subscription is often inefficient and unwelcome.
SpatAI adopts a "Pay-As-You-Go" Token Model, a structure that mirrors the utility of a car engine: you purchase the vehicle (the software license), but you only pay for the fuel (tokens) when you actually drive it.
The Complexity of Implementation : While a subscription model is trivial to implement (a simple binary check of "active" or "inactive"), a token-based system requires a sophisticated, real-time metering infrastructure. The application must track micro-transactions for every prompt, securely synchronizing the user’s balance with the cloud.
SpatAI’s backend normalizes the complex billing of the AI provider—where Input, Output, and Cache tokens have varying costs—into a single, transparent "Token" currency for the user. This ensures that the user is never billed for time, only for the actual value generated.
To facilitate immediate experimentation, every license of SpatAI includes a substantial initial deposit of tokens. Refill packs, when needed, deposit this same amount to the user's account.
Because the system is dynamic, there is no fixed "price per prompt"; the cost depends entirely on the length of the user's input and the complexity of the mathematical solution generated by the AI. However, to provide a practical benchmark: A token refill pack is estimated to cover approximately 200 prompts.
Optimization via Context Caching : This model also encourages efficient workflow habits through Context Caching. The "First Prompt" of a session is computationally the heaviest, as it must load the extensive system instructions that teach the AI the mathematics of spatial audio.
However, SpatAI leverages advanced API caching to "freeze" this context.
- The First Prompt: Uploads the "brain" of the system (Higher cost).
- Subsequent Prompts: The system reads from the cache rather than reprocessing the instructions (Significantly lower cost).
Links :
- https://www.sonic-lab.com/spatai/
- https://plugins.iem.at/
- https://holophonix.xyz/
- https://forum.ircam.fr/projects/detail/spat/
- https://forum.ircam.fr/projects/detail/panoramix/
- https://jp.yamaha.com/products/proaudio/afc/index.html
sonicLAB is a registered trademark of sonicPlanet LTD., UK.
www.sonic-lab.com

Sinan Bökesoy
Sinan Bökesoy is a composer, sound artist and principal developer of sonicLAB and sonicPlanet. Holding a Ph.D. in computer music from the University of Paris8, under the direction of Horacio Vaggione, Bökesoy has carved a niche for himself in the synthesis of self-evolving sonic structures. Inspired by composer greats such as Xenakis, his work leverages algorithmic approaches, mathematical models, and physical processes to generate innovative audio synthesis results. Bökesoy strives to establish a balanced workflow that bridges theory and practice, as well as artistic and scientific approaches. Bökesoy has presented his work at prestigious venues such as Ars Electronica / Starts Prize, IRCAM, Radio France Festival, and international biennials and art galleries. He has published and presented multiple times at conferences including ICMC, NIME, JIM, and SMC, as well as in the Computer Music Journal, MIT Press.
Article topics
Article translations are machine translated and proofread.
// Similar articles